
 天天影视网
天天影视网
巨匠好,我是尹烨。你知说念全宇宙能够存储数据的最高效的载体是什么吗?我们齐活在了一个信息爆炸的年代,每一天互联网上的数据到底有多大?据统计2023年我们国度的数据总量是32.85ZB(泽字节),一个ZB绝顶于10的21次方字节,你不错算一下,一天即是900亿个GB。
而放到全宇宙,2023年概况是120个ZB,到2025年这个数字将达到175个ZB。
数据存储的需求
这样多数据齐放哪儿?除了存储在各个结尾,你的手机里有,我的手机里有,大部分数据可能齐放在数据中心里了。
全宇宙概况有600个超大范围的数据中心,基本上每一个数据中心平均有跳动5000台办事器。关联词即使如斯,我们如故跟不上日益增长的数据存储需求,巨匠想想我方的手机是不是很快就满了。是以,每过两年又得重新再多建100个超大范围的新的数据中心。
天然这个数据中心不是你想建就建的。每一个数据中心它的背后内容是动力撑执,要大齐的电力撑执,不仅高能耗还会对环境产生负面影响,不错说数据存储就像我们今天的超等诡计相通,是全宇宙齐头大的问题。那能不可有一种更高效、更板滞耗的数据存储神情?
我时常说,与其东说念主类自研,不如说念法天然,要以天然为师。东说念主类搞不定的问题就要从人命里去寻找,连年来DNA存储成为这个鸿沟炙手可热的参谋热门。
DNA也能存东西吗?天然能。我们每一个东说念主,每一个蓝鲸,每一个大象,齐来自于一个受精卵,那一个受精卵是何如知说念你是东说念主如故蓝鲸如故大象的?
就因为我们的基因组,是以每个东说念主来例如的话,我们的遗传信息齐写在了30亿个碱基对内部。爸爸30亿,姆妈30亿,合在沿路即是一个受精卵。它们存储在一个受精卵内,这个内部的DNA的全齐的物资量唯一6个皮克(pg),皮克是10的-12次方克,是以姆妈通过280天就把这一个受精卵推广了1万亿份。
你变成荣达儿呱呱落地的时候,你是刚好差未几即是1万亿个细胞,是以姆妈是很锐利的,这个复制的遵守要比我们的硬盘强多了。

若是我们能用扫数的DNA来存储东说念主类的文雅数据,一公斤DNA就够了。1克DNA表面极限上能存储的数据是455个EB,况且DNA分子相等雄厚,低温条目下能存数千年以至更长的时刻。是以它有相等大的后劲,能够成为一种全新的高密度冷存储的介质。
既然DNA存储这样高效,为什么莫得实施应用呢?
第一个即是写它的资本相比高,你要把这些数据0101变成ATCG,然后再把它合成出来,这个本事目下还不够熟习。2022年有一个综述预估,若是在DNA内部写一个TB的数据,资本需要8亿好意思元,这个资本乍一听瑕瑜常炸裂关联词也无谓咂舌。
当年第一个东说念主的基因组(测序)我们花了38亿好意思元,今天只须花100好意思元就够了,是以我们如故把这个问题留给本事和时刻。
第二个问题是,内容我们目下的测序的本事的问题,即是它的这种读写妥协锁的速率齐相比慢。天然DNA的测序资本依然比合成资本低好多了,关联词比传统的数据的存储神情如故高。
比如说放到硬盘,放到U盘,随时齐不错读取的这叫热存,刚才说的那种神情叫冷存。这种冷存储内容上你不错冻在那边,往往常使用,但读出来的时候你如故要用测序的。
就像畴昔我们拿光驱读光盘,目下你要拿测序仪去读它的DNA信息,如故要用专科确实立,专科的东说念主员,他的读取的门槛,包括它的反应速率齐如故不够的。
举牌DNA存储新行径
本年10月份,来自亚利桑那州立大学,包括北大诡计机学院的一个集会团团队,在nature上发了一个著述。他们别具肺肠,驾驭DNA的甲基化来存信息。

什么叫甲基化?浅薄的讲,甲基化是我们DNA上的一种表不雅遗传修饰。举个例子,若是一副扑克牌的后头齐相通,我们管它叫DNA,关联词若是你出了老千,在一部分牌上标注了一些象征,我们就不错去管它叫甲基化。
绝顶于我们在DNA内部的碱基,每个东说念主给戴了一个甲基的帽子,原本即是一个氢,目下变成了一个甲基,它就变成这样一个基团了。
它干什么呢?它好像莫得转换基因序列,但它却能够调控基因的抒发。在东说念主类的细胞内概况往常的景况下,1%的DNA内容上是处于甲基化景况。
通过这样的神情何如来竣事DNA存储呢?
当先他们准备了一条单链的DNA载体,以及一堆不错跟载体互补的短链的DNA,然后他们按照要存储的信息,一一为短链上的这些DNA碱基给它戴帽子:编码是1的话戴帽子;编码是0就不戴帽子。
用这样的神情把数据扔到了DNA里,然后在一些酶的催化下,带着数据的短链DNA会我方因为A对T,G对C,安宁地就补到了互补的那条DNA载体上,酿成了一个完整的DNA双链。同期又在另外一个甲基治愈酶的作用下,这些甲基化的信息就会平行地,内容上是把柄碱基互补旨趣,把它复制到了你启动准备的这个长的DNA载体链上。
临了你把这个载体链测个序,我们就能知说念原本它这里的信息,把柄0101,我就知说念你在告诉我什么了。
这个存储神情的优点在于它无谓我们一个一个碱基去合成DNA,只需要在目下通用的DNA上,通过苟且的甲基化来编码0和1,从而竣事信息的存储。它的破耗的时刻和资本齐大大裁汰了。
光有一个表面还不行,我们还得举一个实真实在的案例。参谋团队把一个中国汉代老虎的拓印图,还有一张熊猫的彩色图片齐放到了DNA里。老虎的拓印图大小是16833个字节,很小的一个图片,它分红了48个条形码,以刚才的这种甲基化的神情存到DA里。
然后第一次拓印收场以后测了一下,准确度唯一90.35%,然后还得重新去迭代一些算法。第二次准确率依然达到了93.6%了。
参谋东说念主员就发现,原本是识别好多甲基化位点的准确率相比低。把这些位点再排斥之后,准确率就从93.6%到了96.3%,再不绝给一个编码纠错有预备,临了数据终于完全规复。
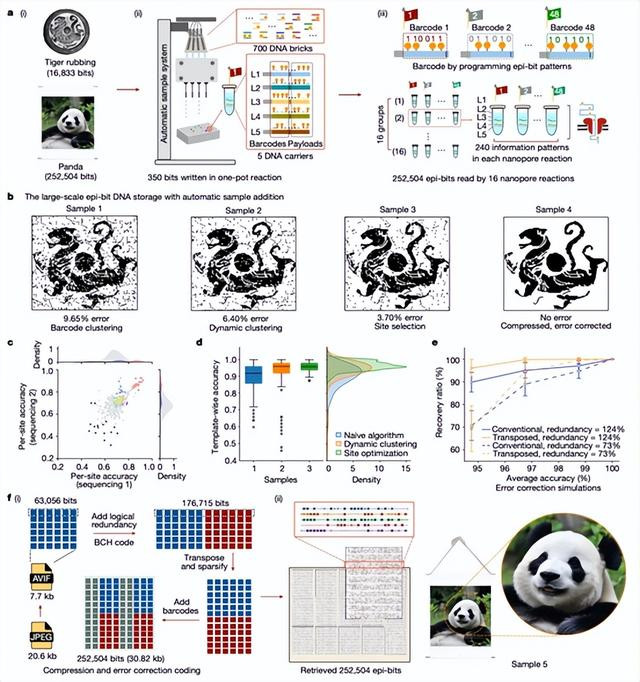
通过这样的一个历练出来的有预备,再去存储比这个老虎图片大的好多的熊猫彩色图片,这个图片有252504个字节,图像赢得了无缺的规复。即是通过一启动的历练赢得一个好的算法,然后再把它付诸于应用。
我祥和DNA存储这个鸿沟依然好多年了,至少在2016年启动,我就依然启动在公开的时局不停的保举这样的一个本事,包括我的科普竹帛《人命密码》《了不得的基因》齐讲过DNA存储本事。

是以当我看到这个来自于北大诡计机学院的集会参谋效果,我也感到相等的怡悦。通过表不雅遗传来存储信息的想路可谓别出机杼,也有望为我们DNA存储本事拓荒一条新的说念路。
我也相等盼望看到这个本事的熟习,毕竟用有机碳存储,而不是用无机硅存储,是东说念主类跟天然学习的一个突出好的神情,也但愿到那一天,数据存储对东说念主类来讲将不再是问题。
您对DNA存储本事有什么成见?接待留言共享天天影视网。